
Identity-preserved Human Detection (FG'20)
Dataset description
The dataset
When using this dataset please cite us:
@inproceedings{clapes2020chalearn, title={ChaLearn LAP 2020 Challenge on Identity-preserved Human Detection: Dataset and Results}, author={Clap{\'e}s, Albert and Junior, Julio CS Jacques and Morral, Carla and Escalera, Sergio}, booktitle={2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020)}, pages={801--808}, year={2020}, organization={IEEE} }
This is a freshly-recorded multimodal image dataset consisting of over 100K spatiotemporally aligned depth-thermal frames of different people recorded in public and private spaces: street, university (cloister, hallways, and rooms), a research center, libraries, and private houses. In particular, we used RealSense D435 for depth and FLIR Lepton v3 for thermal. Given the noisy nature of such commercial depth camera and the thermal image resolution, the subjects are hardly identifiable. The dataset contains a mix of close-range in-the-wild pedestrian scenes and indoor ones with people performing in scripted scenarios, thus covering a larger space of poses, clothing, illumination, background clutter, and occlusions. The scripted scenarios include actions such as: sit on the sofa, lay on the floor, interacting with kitchen appliances, cooking, eating, working on the computer, talking on the phone, and so on. The camera position is not necessarily static, but sometimes held by a person. The data were originally collected as videos from different duration (from seconds to hours) and skipping frames where no movement was observed. The ordering of frames is removed to make it an image dataset, although the video ID is still provided.
Download links
We provide Depth and Thermal separately for those who want to download only one of them.
- Depth (IPHD challenge data)
- Training (84818 frames with groundtruth), either
- Validation (12974 frames without groundtruth), either
- Manually download a splitted zip-file parts ( Part 0 | Part 1 | Part 2 ) and re-join* them, or
- Use download_depth_valid.py.
- Validation groundtruth: Download
- Test (15115 frames without groundtruth), either
- Manually download a splitted zip-file parts ( Part 0 | Part 1 ) and re-join* them
- Use download_depth_test.py.
- Test groundtruth: Download
- Thermal -> Depth (IPHD challenge data)
- Thermal (original: 160x120, undistorted, unregistered to Depth) NEW
The password to decompress the IPHD test data is: "hWy3GZ5.<4cTU'kM" (not including the double quotation marks).
(*) Depth's training and validation zip files have been splitted into 4GB parts using the split Linux command. To re-join them:
- In Linux and MacOS, open a terminal, navigate where Part files were downloaded, and run:
$ cat iphd_train_depth.zip.* > iphd_train_depth.zip
$ zip -T iphd_train_depth.zip # simple check to test everything is okay
$ unzip iphd_train_depth.zip
- In Windows, open Windows Command Line (cmd.exe) and navigate where Part files were downloaded, run
copy /b iphd_train_depth.zip.* iphd_train_depth.zip
and decompress as you normally would.
Dataset structure
Decompressing the data, you will find three folders:
- Images/, a folder containing depth/thermal images.
- Labels/, a folder containing groundtruth: .txt files corresponding to each frame in Images.
- list.txt, a file listing all the images in Images.
Both image and label files share the same filename, but differ in the file extension. The filenames consist of two parts: the video identifier and the frame identifier, e.g. "vid00057_8vpTIK5t.".
Images folder
It contains the set of images in PNG format.
Depth data are 1-channel 16-bit images of size 1280x720. Each pixel in a depth image represents the distance to the depth camera in millimeters (mm). The zero-valued (depth = 0) pixels are error readings that can be caused by several factors. This are normally border pixels in human silohuettes or objects. Errors can be also caused by material reflective properties (shiny floors, mirrors, etc) or strong illumination sources (either from the Sun or bulbs). The data has been recorded using an Intel RealSense D435 device.
Thermal data are 1-channel 16-bit images of size 213x120. Each pixel in a thermal image represents the absolute temprature in Kelvin (K) degrees times 100. So, for instance, a pixel value of 37315 is a temperature reading of 373.15 K. Since thermal is registered to depth, the thermal frames can also contain zero-valued pixels derived from depth errors. An erroneous depth impedes finding the thermal-to-depth pixel correspondance. Take also into account the original size of thermal frames is 160x120, but lateral bands of 0 values were added to match the aspect ratio to depth frames and ease the spatial registration. The data has bee ncaptured using a FLIR Lepton v3 sensor.

Figure 1. Example of depth (left) and thermal (right) images normalized and colormapped to ease visualization.
Labels folder
Each label file (.txt) contains the bounding box annotations for the corresponding frame. It contains a set of rows, one row per human bounding box. Following the YOLOv3 standard format of annotations, the five (5) values of each row respresent:
- Class_id, the id of the human class. For our problem, we are only considering humans, so this is a constant value of 0. It was left in the annotations to fit YOLOv3 annotations' format. You can ignore it.
- x, center of the bounding box along horizontal axis of the image. Normalized to [0,1].
- y, center of the bounding box along vertical axis of the image. Normalized to [0,1].
- width, width of the bounding box. Normalized to [0,1].
- height, height of the bounding box. Normalized to [0,1].
The normalization of x, y, width, and height allows us to use the exact same labels for the images of Depth and Thermal despite having different image resolutions.
Annotation procedure and "weak" training/validation cross-modal labels
Annotation (bounding boxes) was done manually following the annotation guideline of PASCAL VOC 2012, plus one additional constraint: a box has to contain at least 20% of valid pixels (these are non-depth-error pixels and depth value of less than 10 meters. This way we discard human annotations of far-away blobs that could be confused with depth noise or that are simply very small bounding boxes for our low-resolution thermal images.
The data has been annotated by two human annotators. For tranining/validation data, this has been done on the Color modality (not provided). To be able to use the color labels in depth and thermal, all the three modalities had to be spatiotemporally aligned beforehand. Although spatial registration is accurate, there can be temporal missalignment for dynamic scenes. Therefore, the provided cross-modal labels should be better considered "weak" labels. For the test data, however, we minimized this as much as possible by a better spatiotemporal synchronization (see the aligned thermal in Video 1) and a much more careful and exhaustive manual supervision on depth/thermal modalities individually. More details on this in the next section.
Video 1. Thermal data aligned to depth.
Spatial registration and time synchronization
Registration and synchronization are crucial in order to be able to use the Color annotations for Depth/Thermal and, also, to successfully exploit complementary information between Depth and Thermal in any promising fusion method.
For the spatial registration, Depth is on-the-fly registered to Color by RealSense. Thermal however is spatially registered to Depth by our own off-line procedure. See the schematic in Figure 2. Having Depth registered to Color and Thermal to Depth, we have all the modalities registered to the same common space (Color) where the annotations lay.

Figure 2. Depth is on-the-fly registered to Color at capturing time by RealSense. Instead, Thermal to Depth required our own offline registration.
While the spatial registration accuracy is near pixel level (see in Figure 3) on static scenes, regarding the temporal synchronization there can be some missalignment on dynamic scenes with rapid movements. This is due to two factors:
- Color and Depth sensors in Intel's RealSense D435 are placed in different PCB boards and not synchronized at hardware level, but via software. In practice, this means a temporal missalignment up to half of the acquisition frame rate. See [5].
- The low framerate of Lepton (8.7Hz) and RealSense's frame rate drop (from 30Hz to near 10~15 Hz) when performing on-the-fly Depth-to-Color spatial registration.

Figure 3. Spatial registration accuracy. From left to right and up to bottom: color, depth, thermal, depth to color registration, depth and thermal overlay without registration, and thermal to depth registration.
Visualization of thermal images
Visualization of thermal images can be tricky after they have been registered to depth. Depth images contain errors which impede a valid mapping of some thermal pixels to depth image space. We set these thermal pixels also to 0 (as depth error ones). Besides neighboring pixels to those error pixels that are mapped during the registration can be affected by the interpolation used in the mapping function, causing these to take near-zero or intermediate values (non-plausible temperature readings). This phenomenon increases the range of thermal pixel values, compresses the more plausible thermal readings altogether, and directly normalizing and colormapping not achieving good enough contrast.
Try for instance to visualize a thermal image using Python and OpenCV with the following code:
import cv2 im = cv2.imread('Images/vid00191_0G4cSQkk.png', cv2.IMREAD_UNCHANGED) # if no flags, will convert to 8-bit 3-channel minval, maxval, _, _ = cv2.minMaxLoc(im) im = (255 * ((im - minval) / (maxval - minval))).astype(np.uint8) im_cmap1 = cv2.applyColorMap(im, cv2.COLORMAP_HOT) cv2.imshow("im_cmap1", im_cmap1) cv2.waitKey()
The result will be:
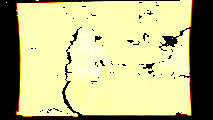
If we take a look at the histogram of thermal pixel values:
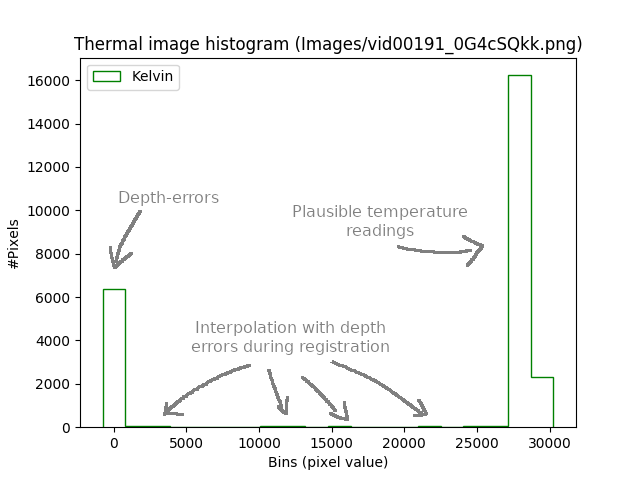
The simpliest solution in order to better visualize the image is to clip unplausible thermal readings:
im = cv2.imread('Images/vid00191_0G4cSQkk.png', cv2.IMREAD_UNCHANGED) im[im < 28315] = 28315 # clip at 283.15 K (or 10 ºC) im[im > 31315] = 31315 # clip at 313.15 K (or 40 ºC) im = (255 * ((im - 28315.) / (31315 - 28315))).astype(np.uint8) im_cmap2 = cv2.applyColorMap(im, cv2.COLORMAP_HOT) cv2.imshow("im_cmap2", im_cmap2) cv2.waitKey()

Evaluation metric
Following the evaluation of PASCAL-VOC and COCO object detection datasets, we will measure average precision (AP); namely, mean average precision (mAP) when APs over different classes are averaged. In our case, there is only the human class.
AP is measured at a fixed intersection-over-union (IoU) value. The IoU value determines how much overlap is required between a detection and potentially matching groundtruth annotations in a frame to be able to count the detection as a true positive (TP). PASCAL VOC uses AP at IoU = 0.5 – namely AP@0.5 –, whereas COCO averages AP at different IoU values (from 0.05 to 0.95).
Having fixed the IoU value, AP can be computed following the explanation from Everingham et. al:
For a given task and class, the precision/recall curve is computed from a method’s ranked output. Recall is defined as the proportion of all positive examples ranked above a given rank. Precision is the proportion of all examples above that rank which are from the positive class. The AP summarizes the shape of the precision/recall curve, and is defined as the mean precision at a set of eleven equally spaced recall levels [0,0.1, . . . ,1]:
The precision at each recall level r is interpolated by taking the maximum precision measured for a method for which the corresponding recall exceeds r:
where p(˜r) is the measured precision at recall ˜r. The intention in interpolating the precision/recall curve in this way is to reduce the impact of the “wiggles” in the precision/recall curve, caused by small variations in the ranking of examples. It should be noted that to obtain a high score, a method must have precision at all levels of recall – this penalizes methods which retrieve only a subset of examples with high precision (e.g. side views of cars).


Differently from Everingham et. al's AP, we do not define 11 equally spaced intervals but as many as instances in the validation/test set, as in the implementations of [1,2,3]. For more detail, check the evaluation script, which is also provided in the "starting kit" fo participants of the CodaLab competition, linked in FG2020's ChalearnLAP Challenge on Identity-preserved Human Detection.
For the purpose of FG2020's ChalearnLAP Challenge on Identity-preserved Human Detection, AP@0.50 will be used to rank the performance of participants' methods. The relatively lower IoU, i.e. 0.5, has been set in order to compensate for the "weak" cross-modal labels.
References
[1] https://github.com/rbgirshick/py-faster-rcnn
[2] https://github.com/eriklindernoren/PyTorch-YOLOv3
[3] https://github.com/ultralytics/yolov3
https://data.chalearnlap.cvc.uab.es[4] https://github.com/pjreddie/darknet/blob/master/cfg/yolov3-tiny.cfg.
[5] https://forums.intel.com/s/question/0D50P0000490RYXSA2/hardware-sync-of-color-and-depth-in-d435?language=en_US
News
There are no news registered in Identity-preserved Human Detection (FG'20)