
2020 Looking at People Fair Face Recognition challenge ECCV
Challenge description
Overview
The task: The participants will be asked to develop their fair face verification method aiming for a reduced bias in terms of gender and skin color (protected attributes). The method developed by the participants will need to output a list of confidence scores given test ID pairs to be verified (either positive or negative matches). Both the bias and accuracy of the method will be evaluated using the provided face dataset (plus individual protected and legitimate attributes and other metadata, as well as identity ground truth annotations).
The dataset: We present a new collected dataset with 13k images from 3k new subjects along with a reannotated version of IJB-C [1] (140k images from 3.5k subjects), totalling ~153k facial images from ~6.1k unique identities. Both databases have been accurately annotated for gender and skin colour (protected attributes) as well as for age group, eyeglasses, head pose, image source and face size, see Fig.1.

Fig.1: Samples from same subject ID, showing high intra-class variability in terms of resolution, headpose, illumination, background and occlusion.
Evaluation: Submitted models will be evaluated for bias in terms of causal effect of the protected attributes to the verification accuracy while adjusting for the other attributes. The final ranking of each model will depend both on its bias and accuracy with the emphasis on bias. The challenge will run on CodaLab, an open-source platform, co-developed by the organizers of this challenge. Data sanity check and beta-testing has been already performed, implementing a ResNet Siamese baseline network, reaching a score of ~89% just for the accuracy score term (at development phase). This leaves a great room for improvement and experimentation for the challenge participants.
Winning teams will receive a travel grant from our sponsors to attend and present their solutions at the ECCV workshop of the challenge. Participants' methods are also welcome as a paper submission to the workshop. Top ranked participants will be also invited to join a paper preparation on the topic of the challenge to a relevant venue (i.e. CVPR/TPAMI).
This is the first time we run this competition and provide these data, but we have a vast experience in challenge organization (we ran more than 20 competitions at NeurIPS, CVPR, ECCV, ICCV, being challenge chair in most of those conferences). ChaLearn and AnyVision are providing travel grants to top ranked participants to attend ECCV and present their results at the associated workshop.
[1] IARPA Janus Benchmark - C: Face Dataset and Protocol. Brianna Maze etal.; International Conference on Biometrics (ICB), pp. 158-165, 2018.
Important dates
Schedule already available.
Dataset
Detailed information about the dataset (e.g., data split, statistics, download links) can be found here.
Baseline
We provide a baseline on the given task in order to set a reference point in terms of minimum required scores regarding face verification accuracy and the positive/negative bias scores associated. We implemented a well-known standard solution for the face verification task based on a Siamese network [2] over a ResNet50 [3] backbone architecture (pretrained on faces). Standard bounding box regression network for face detection was applied to detect the face region in every single image. Training pairs were generated by considering a subset of the dataset with highest possible diversity in terms of legitimate attributes. These pairs were fed to the model in balanced batches of 16 samples (splitted into 8 positive pairs and 8 negative pairs). The system was optimized with respect to maximizing only face verification accuracy confidence. Finally, validation and test scores for the given pairs were passed through the bias and accuracy evaluation metrics, resulting in the baseline values shown in the leaderboard.
[2] Sumit Chopra, Raia Hadsell, and Yann LeCun, Learning a Similarity Metric Discriminatively, with Application to Face Verification, Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), Volume 1, 2015, Pages 539–546.
[3] Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun, Deep Residual Learning for Image Recognition, IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'16), 2016.
How to enter the competition?
![]()
The competition will be run on CodaLab platform. Click here to access our 2020 ECCV ChaLearn Fair Face Recognition Challenge.
The participants will need to register through the platform, where they will be able to access the data and submit their predicitions on the validation and test data (i.e., development and test phases) and to obtain real-time feedback on the leaderboard. The development and test phases will open/close automatically based on the defined schedule.
Starting-kit
We provide a submission template (csv file) for each phase (development and test), with evaluated pairs and associated random predictions. Participants are required to make submissions using the defined templates, by only changing the random predictions by the ones obtained by their models. The predictions (scores) are floating point numbers indicating a confidence, that the image pair contains the same person. The numbers don't have to be normalized into some given interval, but higher score must indicate higher confidence. For example, if the algorithm used cosine similarity of the face feature vectors, score 1 would indicate 100 % confidence, that the image pair contains the same person, whereas score -1 would mean, that the pair is definitely negative. Note, the evaluation script will verify the consistency of submitted files and may invalidate the submission in case of any inconsistency.
Development phase: Submission template (csv file) can be downloaded here.
Test phase: Submission template (csv file) can be downloaded here.
Making a submission
To submitt your predicted results (on each of the phases), you first have to compress your "predictions.csv" file (please, keep the filename as it is) as "the_filename_you_want.zip". Then,
sign in on Codalab -> go to our challenge webpage on codalab -> go on the "Participate" tab -> "Submit / view results" -> "Submit" -> then select your "the_filename_you_want.zip" file and -> submit.
Warning: the last step ("submit") may take few seconds (just wait). If everything goes fine, you will see the obtained results on the leaderboard ("Results" tab). Note, Codalab will keep on the leaderboard the last valid submission. This helps participants to receive real-time feedback on the submitted files. Participants are responsible to upload the file they believe will rank them in a better position as a last and valid submission.
Evaluation metric
There are many ways of measuring the bias. Traditional criteria (e.g. Equality of Opportunity or Predictive Parity [4]) are based on comparing certain statistics of observed data, which makes them easy to calculate, but there is no theoretically justified way of deciding which one is meaningful for a given scenario. Recently, there has been a number of new methods based on causal inference [5]. They start with a "model of the world" given as a causal diagram [6] and the final objective is then simply derived from this model. Unlike the traditional objectives, causal models explicitly formulate our views on ethical principles and expose them to criticism, which opens the discussion about fairness to much larger audience.
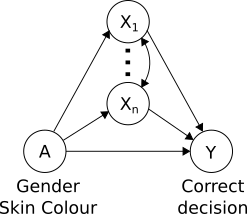 In this challenge, the measure of fairness is derived from a causal diagram shown in the image on the right hand side in terms of a causal effect of protected attributes A (gender and skin colour - male bright, male dark, female bright, female dark) to correct decision Y of the algorithm. The diagram also assumes that there are other attributes Xi (e.g. age, wearing glasses, head pose etc.) that influence the accuracy too and might be caused by A as well as by other Xi.
In this challenge, the measure of fairness is derived from a causal diagram shown in the image on the right hand side in terms of a causal effect of protected attributes A (gender and skin colour - male bright, male dark, female bright, female dark) to correct decision Y of the algorithm. The diagram also assumes that there are other attributes Xi (e.g. age, wearing glasses, head pose etc.) that influence the accuracy too and might be caused by A as well as by other Xi.
Not all attributes Xi are treated in the same way. For example wearing glasses is a legitimate reason for lower accuracy and if people from one protected group wear them more often than other groups, the lower accuracy shouldn't be seen as discriminative. More formally, in order to remove a possible influence of this variable to measured bias, we remove the causal link by intervening on the value of the corresponding Xi. For some attributes the interventions are not feasible in real life, for example it is not possible to forcibly change people's age, but causal inference allows us to simulate such action. On the other hand consider a hypotetical algorithm which takes into account the place of residence (e.g. by using more accurate model in some neigbourhoods and less accurate in the others). This practice (also known as redlining) is unfair, because in some cities the place of residence is a proxy for skin colour. Therefore when deriving the objective, we must take these links into account. In this competition we consider five legitimate attributes (age group, wearing glasses, head pose, source of the image (single image or video frame) and size of the bounding box) and no proxy attributes.
Informally, we say that an algorithm is fair, if for all combinations of values of legitimate attributes it achieves the same accuracy for all protected groups. A numerical objective is obtained from this principle as follows. For given values of the legitimate attributes X=x we define a discrimination da(X=x) of a protected group A=a as a difference in accuracy for this group and a group with the best accuracy:
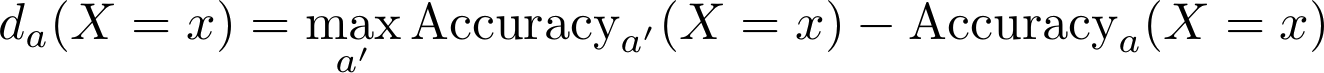
The final measure of unfairness is then the difference between the average discrimination of the most discriminated group and the least discriminated one:
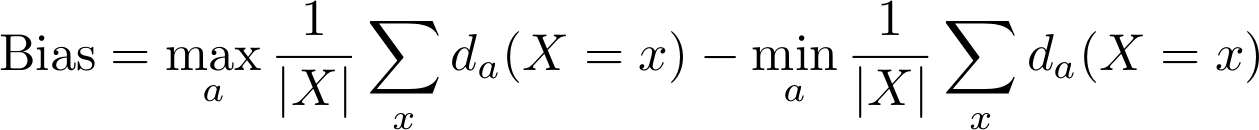
where |X| denotes the number of combinations of values of legitimate attributes. We use AUC - ROC to measure the accuracy.
You can download the evaluation script here.
[4] Sahil Verma, Julia Rubin, Fairness definitions explained, Proceedings of the International Workshop on Software Fairness. FairWare ’18, New York, NY, USA, ACM (2018) 1–7.
[5] Joshua R. Loftus, Chris Russell, Matt J. Kusner, and Ricardo Silva. Causal reasoning for algorithmic fairness, arXiv preprint arXiv:1805.05859, 2018.
[6] Judea Pearl, Causal inference in statistics: An overview, Statistics Surveys 3 (2009) 96–146
Ranking strategy, Leaderboard and basic Rules
The leaderboard on Codalab will show 2 bias scores and 1 accuracy value, as illustrated below.

Participants will be ranked by the average rank position obtained on each of these 3 variables. This way, bias is receiving more weight than accuracy. However, to prevent a random number generator from winning the competition (random results are inherently unbiased and therefore the adopted ranking strategy would rank them as very good) we require that the accuracy of the submissions must be higher than the accuracy of our baseline model. Similarly, the submission of constant values would return Bias score = 0, due to the "max-min" strategy defined in the above section. For this reason the ranking shown on the leaderboard may not be considered as the final ranking.
Basic Rules: According to the Terms and Conditions of the Challenge,
- "in order to be eligible for prizes, top ranked participants’ score must improve the baseline performance provided by the challenge organizers in both verification fairness score and verification accuracy score;" that is, higher accuracy value and lower bias scores.
- "the performances on test data will be verified after the end of the challenge during a code verification stage. Only submissions that pass the code verification will be considered to be in the final list of winning methods;"
- "to be part of the final ranking the participants will be asked to fill out a survey (fact sheet) where a detailed and technical information about the developed approach is provided."
Warning message (May 25): we regret to inform you that we have recently detected an internal misalignment at the column tags shown in the leaderboard referring to bias, i.e., "Bias (positive pairs)" and "Bias (negative pairs)". Since face verification is a binary problem, for interpretability reasons, we internally choose the tag ‘0’ for negative samples and tag ‘1’ for positive samples. However, the leaderboard assumed the opposite assumption. We apology for the mistake associated with the wrong order of labels "positive<->negative" shown in the leaderboard, that cannot be fixed on Codalab after the competition is released. Because of this, you have to consider "Bias (positive pairs)" as "Bias (negative pairs)" and vice-versa, i.e., "Bias (negative pairs)" as "Bias (positive pairs)". That change does not affect your submissions nor the ranking at all, but the acknowledgment you have towards the case in which your algorithms may suffer the most from bias. We hope that has not interfered in your work and we apologize for this inconvenience. Sincerely, The organizing team
Winning solutions (post-challenge)
Important dates regarding code submission and fact sheets are provided here.
- Code verification: After the end of the test phase, top participants are required to share with the organizers the source code used to generate the submitted results, with detailed and complete instructions (and requirements) so that the results can be reproduced locally. Note, only solutions that pass the code verification stage are elegible for the prizes and to be anounced in the final list of winning solucions. Note, participants are required to share both training and prediction code with pre-trained model so that organizers can run it at only test stage if they need.
- Participants are requested to send by email to <juliojj@gmail.com> a link to a code repository with the required instructions. In this case, put in the Subject of the E-mail "ECCVW 2020 FairFaceRec Challenge / Code repository and instructions"
- Fact sheets: In addition to the source code, participants are required to share with the organizers a detailed scientific and technical description of the proposed approach using the template of the fact sheets providev by the organizers. Latex template of the fact sheets can be downloaded here.
- Then, send the compressed project (in .zip format), i.e., the generated PDF, .tex, .bib and any additional files to <juliojj@gmail.com>, and put in the Subject of the E-mail "ECCVW 2020 FairFaceRec Challenge / Fact Sheets"
Prizes (Sponsored by Anyvision)
- 1st place 1000 €
- 2nd place 500 €
- 3rd place 500 €
Challenge Results (test phase)
We are happy to announce the top-3 winning solutions of the 1st ChaLearn Fair Face Recognition and Analysis Challenge, organized in conjunction with ECCV 2020. They are:
-
1st place: paranoidai
-
2nd place: ustc-nelslip
-
3rd place: CdtQin
The final leaderboard (shown on Codalab), Codes and Fact Sheets shared by the participants can be found here.
The organizers would like to thank all the participants for making this challenge a success.
The 2020 Looking at People Fair Face Recognition challenge and workshop ECCV are supported by International Association in Pattern Recognition IAPR Technical Committee 12 (IAPR) and European Laboratory for Learning and Intelligent Systems ELLIS, Human-centric Machine Learning program (ELLIS)

![]()
Check our associated
ECCV'20 ChaLearn LAP workshop on Fair Face Recognition and Analysis