
LSE_eSaude_UVIGO (ECCV'22)
Dataset description
Quick overview
LSE_eSaude_UVIGO is a dataset of Spanish Sign Language (LSE: Lengua de Signos Española) in the health domain (~10 hours of Continuous LSE), signed by 10 people (7 deaf and 3 interpreters) partially annotated with the exact location of 100 signs. This dataset has been collected under different conditions than the typical Continuous Sign Language datasets, which are mainly based on subtitled broadcast and real-time translation. In this case the signing is performed to explain health contents in LSE by reading printed cards, so reliance on signers is large due to the richer expressivity and naturalness. In this sense this is a good dataset to test signer independent performance of the SLR systems.
The dataset is acquired in studio conditions with blue chroma-key, no shadow effects and uniform illumination, at 25 fps and FHD. The added value of the dataset is he rich and rigorous hand-made annotations. Experts interpreters and deaf people are in charge of annotating the full content of the dataset sign by sign. As this is a very large and costly task, the dataset is being partially released for the 2022 Sign Spotting Challenge at ECCV with a selection of annotated signs. Annotation is in progress and upgrades of the annotations will be released in further events.
Annotation
LSE_eSaude_UVIGO is being annotated with the ELAN program. Annotators use a Tier called ‘M_Glosa’ for the location of the selected glosses. In the first release for the ECCV challenge a subset of 100 glosses were spotted. There’s also an associated Tier ‘Var’ for annotating variants of the signed gloss. These variants are linguistic, like slight modifications of the of sign due to relaxed execution (coded LAX), slight change of location in space (LOC), abnormal use of the non-dominant hand (MAN) and morphology changes as in plurals (MPH), or non-linguistic, like very short sign due to speed and large coarticulation SHO), partial oclussion of the sign with other body parts (OCC) or because out of the frame (OUT) and other gloss with similar signed appereance to the selected gloss (SIM). For the sake of simplicity, these variations are not filtered out in the distribution, just informed. In the next video a small sample of the dataset is shown running in ELAN.
The annotation criteria shared by all the annotators (4) is as follows:
- The begin_timestamp for a sign is set as soon as the parameters hand configuration, palm orientation and movement and/or location correspond to that sign more than to the transition from the preceeding one.
- The end_timestamp for a sign is set as soon as the parameters hand configuration, palm orientation and movement and/or location start to chane to a transition to the next sign.
- As far as possible, transitions are not included in the annotated intervals.
- A star ‘*’ prefix indicate that there’s slight drift from normal realization. The reasons can be linguistic (MAN, LOC, MPH, LAX) or not linguistic (SHO, OCC, OUT, SIM)
It is important to highlight the annotation of the plurals. In Spanish sign Language, plurals use to be performed by sign repetition. Annotations for plurals are coded as a single interval comprising all the concatenated repetitions. If there are two anotated signs of the same class_sign very close to each other it means that there’s another sign in the middle (not beloning to the annotated set). Plurals are usually marked as a morphology variation (MPH). The only special case corresponds to the glosses PERSON and its plural PERSON(M-RE), that are coded with different glosses-classes because the second repetition use to be smaller and relaxed, as a rebound without changing the hand configuration. In the video example the gloss PERSONA(M-RE) is followed by *NECESITA (spanish for ‘persons need’). Both are in plural and movements are repeated. NECESITA is repeated in the space and is marked as a the same sign as NECESITA but with a morphology variation (MPH).
Data split and structure
The dataset released for the challenge is divided in 5 splits and a query set for accomodating both Tracks and person-dependent and person-independent evaluations. Track1 is named MSSL (multiple shot supervised learning), and Track2 is named OSLWL (one shot learning and weak labels)
- MSSL_Train_Set: around 2.5 hours of footage with annotations of 60 signs performed by 5 persons (1 left-handed, 1 interpreter, 4 deaf). The footage is divided in video files that contain a unique signer, so the name of each file indicates the code of the signer and a unique sequential number in the dataset, as p##_n###. The .mp4 and annotation files (.eaf and .pkl) have the same name.
- MSSL_Val_Set: around 1.5 hours of footage with annotations of the same 60 signs performed by 4 persons (2 same than MSSL_Train_Set, 2 different). Video file names follow he same rule than MSSL_Train_Set. Annotation files will be released after the development phase.
- MSSL_Test_Set: around 1.5 hours of footage with annotations of the same 60 signs performed by 4 persons (2 same than MSSL_Train_Set and 2 different). Video file names follow he same rule than MSSL_Train_Set. Annotation files will be released after the end of the challenge.
- OSLWL_Query_Set: 40 short videos of 40 isolated signs, different from the MSSL Track. The videos are recorded in two settings: 20 videos recorded by one of the deaf men in the dataset under the same studio conditions, 20 videos recorded by a female interpreter not in the dataset and in another lab setting, so realistic query searches can be evaluated.
- OSLWL_Val_Set: around 1500 files of 4-sec duration containing 1 out of 20 signs each (simulating weak labels), performed by 5 persons. One person is the same that performs 10 sign queries, while the other 10 queries are performed by the external female interpreter. The name of the file indicates the code of the signer, the code of the sign to be retrieved and a unique sequential number in the dataset, p##_s##_n###. As this Track tries to simulate retrieval after weak labeling, around 10% of the video files will not contain any instance of the sign to be retrieved (simulating a misalignment of subtitles and signing, a failure in the weak labeling pipeline or a word not being signed). The annotation files for this set will be distributed after the development phase.
- OSLWL_Test_Set: similar to the OSLWL_Val but changing the 20 query signs and 3 of the 5 signers. The annotation files for this set will be distributed after the end of the challenge.
Basic statistics
In both Tracks, the amount of examples per sign is not uniform, as some signs are common terms but others are related to the specific health topic that is being explained in the videos. Common signs can appear up o 30 times more frequently than the specific signs. The total number of hand annotations exceed 5000 in Track1 (MSSL) and 3000 in Track2 (OSLWL).
The next figure shows some basic statistics of MSSL signs as an example: the count of occurrences for each sign (blue), the mean duration per sign in milisecs (orange), and the standard deviation of the duration also in miliseconds (gray). OSLWL signs share similar numbers.
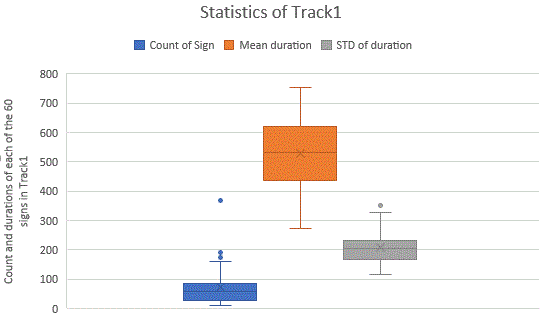
The duration of the co-articulated signs is not a Gaussian variable, starting from 120 ms (3 frames) up to 2 sec (50 frames), with a mean duration of 520 ms (13 frames).
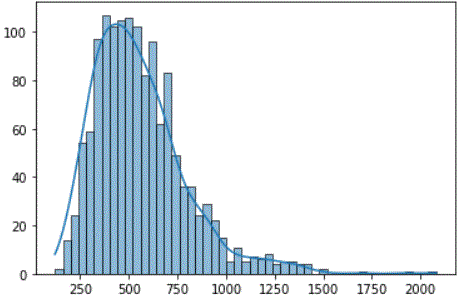
The next figure shows the distribution of durations for the OSLWL_Val_Set, as an example.
Example from MSSL_Train_Set
Download from here a video file from the MSSL_Train_Set, the corresponding ELAN file, the groundtruth file in pickle format and in csv format. Please read the file formats in the starter kit (be aware that class numbers can vary with respect to the dataset distribution)
Link for download
By downloading the data, you agree with the Terms and Conditions of the Challenge. All files are encrypted! To discompress the data, use the associated keys. Note, decryption keys are provided on Codalab after registration, based on the schedule of the challenge.
Dev Phase:
- Track1: MSSL_Train_Set (with lables in .txt, .pkl and .eaf)
- Track1: MSSL_Val_Set (without labels)
- Track2: OSLWL_Query_Set and OSLWL_Val_Set (without labels)
Test Phase:
- Track1: MSSL_Valid_gt (lables in .txt, .pkl and .eaf)
- Track1: MSSL_Test_Set (without labels)
- Track2: OSLWL_Query_Set and OSLWL_Test_Set (without labels)
- Track2: OSLWL_Valid_gt (lables in .txt, .pkl and .eaf)
Post Challenge:
- Track1: MSSL_TEST_SET_GT.zip (test labels)
- Track2: OSLWL_TEST_SET_GT.zip (test labels)
Decryption keys:
- Track1: MSSL_Train_Set (with lables in .txt, .pkl and .eaf) -> SEtNRzeHCHRA9xr6
- Track1: MSSL_Val_Set (without labels) -> P4washbCad9FWJHB
- Track2: OSLWL_Query_Set and OSLWL_Val_Set (without labels) -> nF3cx5eEtqgTUkst
- track 1: MSSL_Valid_gt.zip code: Eu8NdJDL
- track 1: MSSL_Test_set.zip code: PxHyvFux
- track 2: OSLWL_Query_Set-and-OSLWL_Test_Set.zip code: wdzSSVGa
- track 2: OSLWL_Valid_gt.zip code: Q9uMDtga
Post challenge (test labels):
- MSSL_TEST_SET_GT.zip -> P4washbCad9FWJHB
- OSLWL_TEST_SET_GT.zip -> Q9uMDtga
News
There are no news registered in LSE_eSaude_UVIGO (ECCV'22)