
UPAR (WACV'24)
Dataset description
The challenge dataset used in the UPAR Challenge at WACV'24 is a subset of the existing UPAR dataset [1,2]. The challenge dataset consists of the harmonization of three public datasets (PA100K [3], PETA [4], and Market1501-Attributes [5]) with different characteristics and a novel test set. 40 binary attributes have been unified between those for which additional annotations are provided. This dataset enables the investigation of attribute recognition and attribute-based person retrieval methods' generalization ability under different attribute distributions, viewpoints, varying illumination, and low resolutions.
This challenge aims to spotlight the problem of domain gap in a real-world surveillance context and highlight the challenges and limitations of existing methods to provide a future research direction. As can be seen in Fig. 1, the datasets have different characteristics and the distributions of the data vary greatly, compared to different sets of the same dataset.

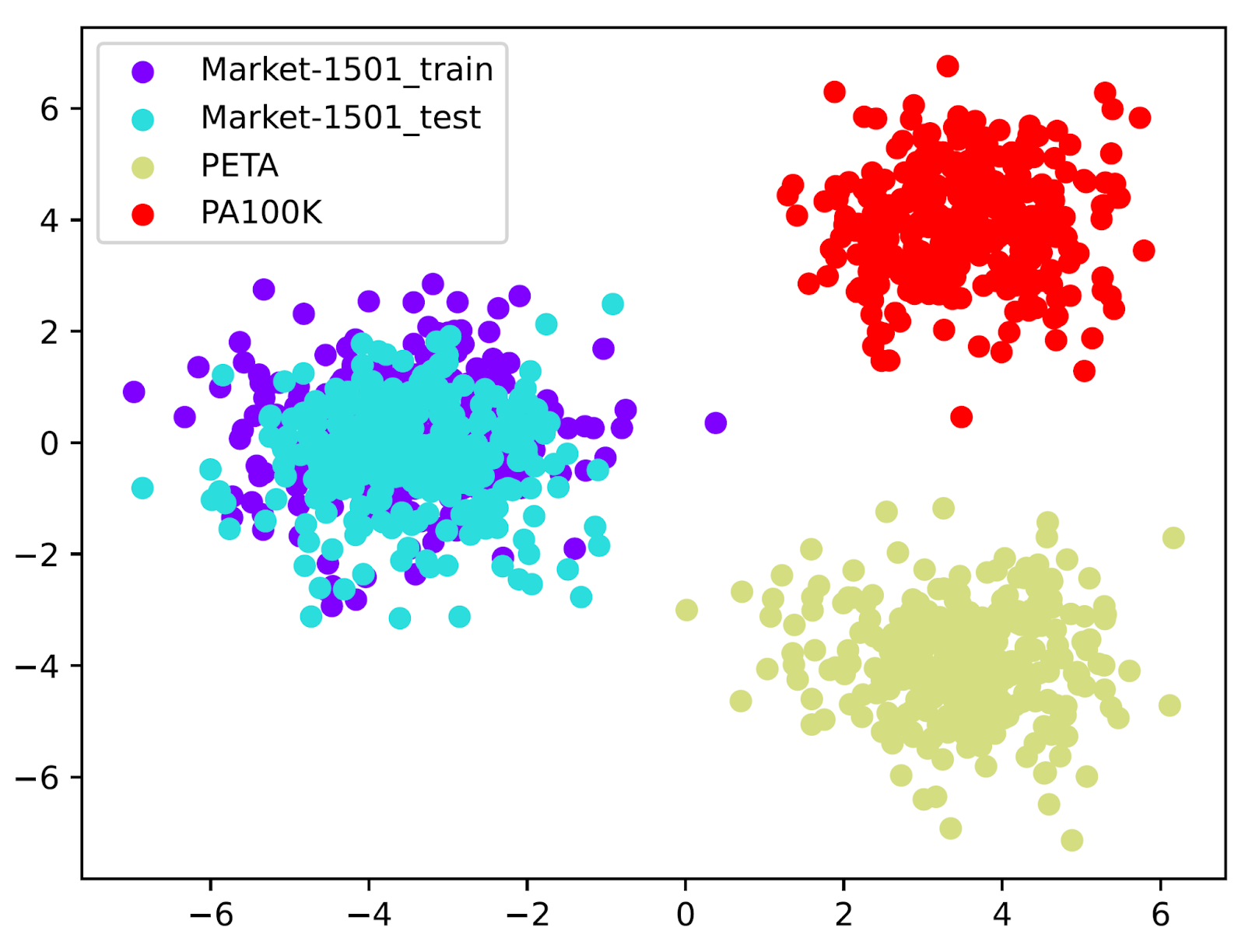
Fig 1. Sample images from the sub-datasets and domain distribution
The following table provides an overview of available attribute categories and associated binary attributes.
|
Category |
Binary Attributes |
|
Age |
"Age-Young", "Age-Adult", "Age-Old", |
|
Gender |
"Gender-Female", |
|
Hair-length |
"Hair-Length-Short", "Hair-Length-Long", "Hair-Length-Bald", |
|
UpperBody-Length |
"UpperBody-Length-Short", |
|
UpperBody-Color |
"UpperBody-Color-Black", "UpperBody-Color-Blue", "UpperBody-Color-Brown", "UpperBody-Color-Green", "UpperBody-Color-Grey", "UpperBody-Color-Orange", "UpperBody-Color-Pink", "UpperBody-Color-Purple", "UpperBody-Color-Red", "UpperBody-Color-White", "UpperBody-Color-Yellow",, "UpperBody-Color-Other",, |
|
LowerBody-Length |
"LowerBody-Length-Short", |
|
LowerBody-Color |
"LowerBody-Color-Black", "LowerBody-Color-Blue", "LowerBody-Color-Brown", "LowerBody-Color-Green", "LowerBody-Color-Grey", "LowerBody-Color-Orange", "LowerBody-Color-Pink", "LowerBody-Color-Purple", "LowerBody-Color-Red", "LowerBody-Color-White", "LowerBody-Color-Yellow",, "LowerBody-Color-Other", |
|
LowerBody-Type |
"LowerBody-Type-Trousers&Shorts", "LowerBody-Type-Skirt&Dress", |
|
Accessory-Backpack |
"Accessory-Backpack", |
|
Accessory-Bag |
"Accessory-Bag", |
|
Accessory-Glasses |
"Accessory-Glasses-Normal", "Accessory-Glasses-Sun", |
|
Accessory-Hat |
"Accessory-Hat", |
Public Splits
The challenge uses training and validation data from three UPAR domains: Market-1501, PA100K, and PETA. The training sets from those datasets are available for training, and validation is done on the test sets. Please note that, in contrast to the last year’s challenge, there is only one training split and data from multiple data sources can be used for training. Moreover, validation is done on data from the same sources to mimic the realistic setting when no data from the actual target domain but development datasets with train and test splits are available during development. You are free to make different experiments with subsets of the training and validation data, or leverage cross-validation schemes during the development phase.
The training data is identical for both tracks (see “train.csv”). Only images specified in the train files can be used for training. The use of any other data is strictly prohibited and will be checked during code verification.
Test Set
Since the challenge aims to investigate methods that generalize well to new and possibly unknown domains without re-training, calibration, or domain adaptation, we only provide little information about the test set. The final challenge winners are selected based on the score achieved on the evaluation server on the novel test set.
The private test set consists of images from one data sources and includes both indoor and outdoor images. Furthermore, image resolutions and camera views vary greatly and pose another challenge.
Links for Download and Challenge Instructions
As mentioned in the challenge description and challenge rules, both tracks have a fixed training set.
-
Track 1: Pedestrian Attribute Recognition: Train on predefined data and evaluate generalization properties.
-
Track 2: Attribute-based Person Retrieval: Train on predefined data and evaluate generalization properties.
By downloading the data using our starting kit, you agree with the Terms and Conditions of the Challenge and comply with the licenses provided for the use of the sub-datasets.
-
Starting kit: https://github.com/speckean/upar_challenge
-
Test data & validation annotations: (decryption key: "UVk4yayzy38zEMKH")
Data Source Licenses
PA-100K Dataset [3]
https://github.com/xh-liu/HydraPlus-Net
License: CC-BY 4.0 license "Creative Commons — Attribution 4.0 International — CC BY 4.0".
PETA Dataset [4]
http://mmlab.ie.cuhk.edu.hk/projects/PETA.html
License: "This dataset is intended for research purposes only and as such cannot be used commercially. In addition, reference must be made to the aforementioned publications when this dataset is used in any academic and research reports."
Market1501-Attributes [5]
License: No license available.
[1] Cormier, Mickael; Specker, Andreas; Jacques, Julio C. S. et al. (2023): UPAR Challenge: Pedestrian Attribute Recognition and Attribute-based Person Retrieval – Dataset, Design, and Results – link
[2] Specker, Andreas; Cormier, Mickael; Beyerer, Jürgen (2023): UPAR: Unified Pedestrian Attribute Recognition and Person Retrieval – link
[2] Liu, Xihui; Zhao, Haiyu; Tian, Maoqing; Sheng, Lu; Shao, Jing; Yi, Shuai et al. (2017): HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis. In: 2017 IEEE International Conference on Computer Vision. ICCV 2017 : proceedings : 22 - 29 October 2017, Venice, Italy. Unter Mitarbeit von Katsushi Ikeuchi. 2017 IEEE International Conference on Computer Vision (ICCV). Venice, 10/22/2017 - 10/29/2017. Institute of Electrical and Electronics Engineers. Piscataway, NJ: IEEE (IEEE Xplore Digital Library), S. 350–359.
[3] Deng, Yubin; Luo, Ping; Loy, Chen Change; Tang, Xiaoou (2014): Pedestrian Attribute Recognition At Far Distance. In: Kien A. Hua (Hg.): Proceedings of the 22nd ACM international conference on Multimedia. the ACM International Conference. Orlando, Florida, USA, 03.11.2014 - 07.11.2014. New York, NY: ACM, S. 789–792.
[4] Lin, Yutian; Zheng, Liang; Zheng, Zhedong; Wu, Yu; Hu, Zhilan; Yan, Chenggang; Yang, Yi (2019): Improving Person Re-identification by Attribute and Identity Learning. In: Pattern Recognition 95, S. 151–161. DOI: 10.1016/j.patcog.2019.06.006.
News
There are no news registered in UPAR (WACV'24)