
2018 Looking at People ECCV Satellite Challenge
Challenge description
![]()
ChaLearn Challenges on Image and Video Inpainting ECCV satellite 2018
Inpainting, the topic of our proposed challenge, refers to replacing missing parts in an image (or video). The problem of dealing with missing data or incomplete data in machine learning arises in many applications. Recent strategies make use of generative models to impute missing or corrupted data. Advances in computer vision using deep generative models have found applications in image/video processing, such as denoising [1], restoration [2], super-resolution [3], or inpainting [4,5]. We focus on image and video inpainting tasks, that might benefit from novel methods such as Generative Adversarial Networks (GANs) [6,7] or Residual connections [8,9]. Solutions to the inpainting problem may be useful in a wide variety of computer vision tasks. We chose three examples: human pose estimation and video de-captioning and fingerprint denoising. Regarding our first choice: it is challenging to perform human pose recognition in images containing occlusions; since tackling human pose recognition is a prerequisite for human behaviour analysis in many applications, replacing occluded parts may help the whole processing chain. Regarding our second choice: in the context of news media and video entertainment, broadcasting programs from various languages, such as news, series or documentaries, there are frequently text captions or encrusted commercials or subtitles, which reduce visual attention and occlude parts of frames that may decrease the performance of automatic understanding systems. Despite recent advances in machine learning, it is still challenging to aim at fast (real time) and accurate automatic text removal in video sequences. Finally, as our third choice: biometrics play an increasingly important role in security to ensure privacy and identity verification, as evidenced by the increasing prevalence of fingerprint sensors on mobile devices. Fingerprint retrieval keeps also being an important law enforcement tool used in forensics. However, much remains to be done to improve the accuracy of verification, both in terms of false negatives (in part due to poor image quality when fingers are wet or dirty) and in terms of false positives due to the ease of forgery.
We propose a challenge that aims at compiling the latest efforts and research advances from the computational intelligence community in creating fast and accurate inpainting algorithms. The methods will be evaluated on two large, newly collected and annotated datasets related to two realistic scenario in visual inpainting. The challenge will be organized in three tracks:
- Image inpaining to recover missing parts of human body (track 1),
- Video inpainting to remove overlayed text in video clips (track 2),
- Inpainting and denoising for fingerprint verification (track 3).
In all cases, the main goal is to generate the visually best possible set of pixels to obtain a complete image or video clip. Some samples are shown in Fig. 1, Fig. 2 and Fig. 3 for all tracks.
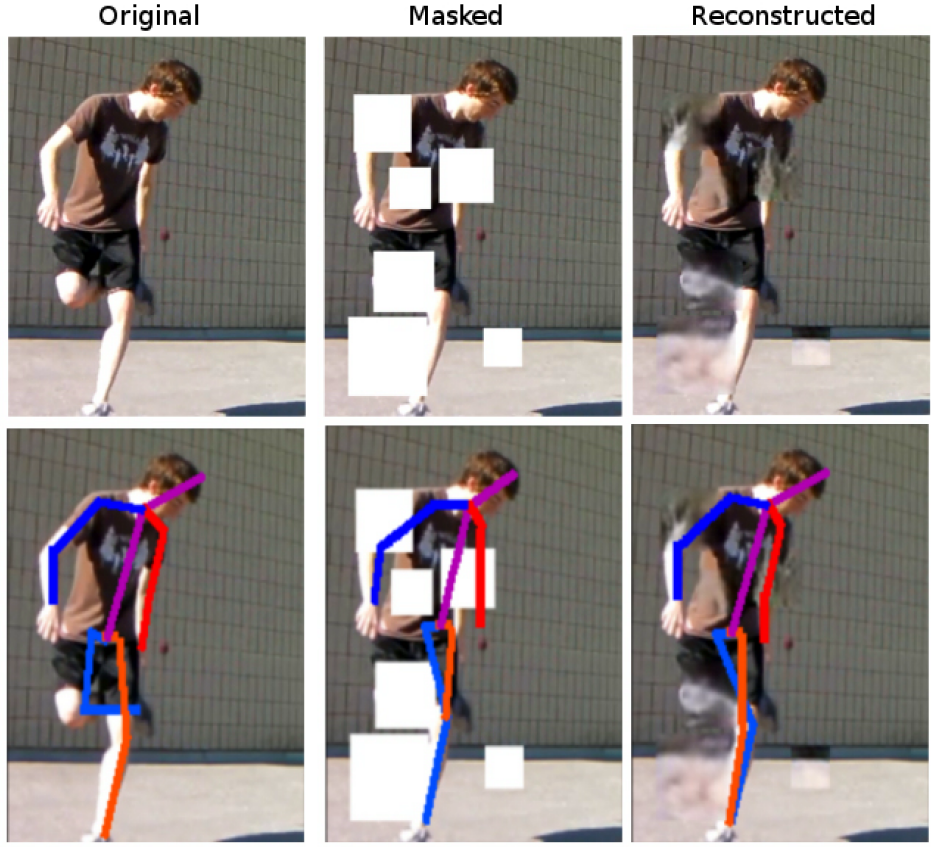
Figure 1. Track1: inpainting missing parts of body and the results for human pose before/after reconstruction

Figure 2. Track 2: Inpainting to remove overlayed text.

Figure 3. Track 3: Inpainting to denoise fingerprint. From left to right: input image, ground truth and reconstructed image.
The competition will be run in the CodaLab platform (https://competitions.codalab.org), an open-source platform, co-developed by the organizers of this challenge together with Stanford and Microsoft Research (https://github.com/codalab/codalab-competitions/wiki/Project_About_CodaLab). The participants will register through the platform, where they will be able to get all necessary data to start the competition.
Codalab is now public. The links are available for each track as:
Track 1: https://competitions.codalab.org/competitions/18423
Track 2: https://competitions.codalab.org/competitions/18421
Track 3: https://competitions.codalab.org/competitions/18426
Winners - For each of the 3 tracks, the prizes are:
1st Winner - 500$ travel grant for ECCV Satellite event + 200$ AWS credits
2nd Winner - 500$ travel grant for ECCV Satellite event + 200$ AWS credits
3rd Winner - 200$ AWS credits
Google (www.google.com), Amazon (https://www.amazon.com/), and Disney Research (https://www.disneyresearch.com/) are Sponsoring competition prizes
Top competition entries are also invited to submit contributions to ECCV Satellite event of the competition. Best contributions will be also invited to submit extended work to IEEE TPAMI Special Issue following the rigurous TPAMI revision procedure.
Protocols
The participants may compete in either or all tracks. Each track will have two phases: feed-back phase and final evaluation phase.
Data will be made available to participants in different stages as follows:
- Development (training) data with ground truth for all of the images and video clips, distributed as starting kit.
- Validation data without missing parts will be also provided to participants at the beginning of the competition. Participants will be able to submit predictions to the CodaLab platform, and receive immediate feedback on their performance on the validation data set (there will be a validation leaderboard in the platform), during the feed-back phase.
- Final evaluation (test) data will be made available to participants one week before the end of the competition (see schedule), for the final evaluation phase.
Given we have unbalanced metrics, the ranks of participants are computed by an average over the ranks of all metrics. Then the first rank is selected as the winner.
Dataset sizes are given as the total of collected/pre-processed images and videos as indicated in Tracks. We split the datasets in each track in 70%-15%-15% for train/validation/test phases. For the feed-back phase, the participants will submit prediction results through the CodaLab platform. For the test phase, we will ask for both for prediction results and code.
References
[1] V. Jain and S. Seung, “Natural image denoising with convolutional networks,” in Advances in Neural Information Processing Systems, 2009, pp. 769–776.
[2] L. Xu, J. S. Ren, C. Liu, and J. Jia, “Deep convolutional neural network for image deconvolution,” in Advances in Neural Information Processing Systems 27, Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, Eds. Curran Associates, Inc., 2014, pp. 1790–1798.
[3] C. Dong, C. C. Loy, K. He, and X. Tang, “Image super-resolution using deep convolutional networks,” IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 2, pp. 295–307, 2016.
[4] J. Xie, L. Xu, and E. Chen, “Image denoising and inpainting with deep neural networks,” in Advances in Neural Information Processing Systems, 2012, pp. 341–349.
[5] A. Newson, A. Almansa, M. Fradet, Y. Gousseau, and P. P´erez, “Video inpainting of complex scenes,” SIAM Journal on Imaging Sciences, vol. 7, no. 4, pp. 1993–2019, 2014.
[6] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in neural information processing systems, 2014, pp. 2672–2680.
[7] D. Pathak, P. Kr¨ahenb¨uhl, J. Donahue, T. Darrell, and A. Efros, “Context encoders: Feature learning by inpainting,” in Computer Vision and Pattern Recognition (CVPR), 2016.
[8] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
[9] X.-J. Mao, C. Shen, and Y.-B. Yang, “Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections,” ArXiv e-prints, Jun. 2016.
[10] C. Yang, X. Lu, Z. Lin, E. Shechtman, O. Wang, and H. Li, “High-resolution image inpainting using multi-scale neural patch synthesis,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
[11] R. A. Yeh, C. Chen, T. Y. Lim, S. A. G., M. Hasegawa-Johnson, and M. N. Do, “Semantic image inpainting with deep generative models,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[12] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004.
News
ECCV Satellite Event and TPAMI
Challenge and associated ECCV Satellite Event and TPAMI special issue on Inpainting and Denoising in the Deep Learning Age!