
Video Decaptioning (WCCI'18, ECCV'18)
Dataset description
We designed a dataset for video inpainting task, as a set of (X, Y) pairs where X is a 5 seconds video clip (containing encrusted text) and Y the corresponding target video clip (without encrusted text). To do so we collected about 150 hours of diverse videos of TV movies of various genre with associated generated subtitles, available from YouTube. The various video contents are intended to be as diverse as possible, making the dataset almost generic for subtitle removal task. Data sources were checked to fulfill the required copyrights to be reused during this challenge for research purposes.
Raw videos have been processed in order to obtain a set of well formed short video sequences: we removed letterboxing area (top/down black bars where subtitles could be printed), normalized frame rate to 25 frames per second and rescaled frames to width=128 keeping aspect ratio, then cropped the center 128x128 region. In order to create the set X of corrupted videos, we hard printed subtitles by applying various variations in fonts and text style (size, color, italic/bold, background box transparent/opaque). Finally, we split the original and corrupted videos in 5 seconds non-overlapped video clips. In the following image we can see an histogram showing which portion of the frames has been occluded by the encrusted text.
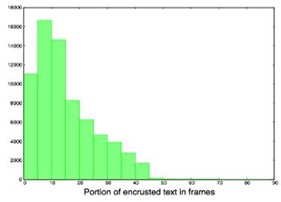
We kept 70% clips that contains the most subtitles, so about 90000 video clips that contain 125 frames of 128x128 pixels. Finally, we split the resulting video clips into 70% train, 15% evaluation, 15% test. The following image shows few samples showing the diversity of video content, style and resolution, and the various fonts transformation and subtitles overlays. We also notice (very) few samples containing text or logo in both corrupted and groundtruth clips.
News
There are no news registered in Video Decaptioning (WCCI'18, ECCV'18)