
Image Inpainting (WCCI'18, ECCV'18)
Dataset description
To tackle this problem participants will be provided with a dataset. The proposed dataset is composed of 41076 images, where each image is centered on a human which may or may not be partially occluded. The ratio of background information in relation to human body is roughly the same for all images although some other humans may appear in the background with an arbitrary size. The humans appear in a lot of poses with a variety of difficulties from simple rigid poses to complicated sport-oriented poses with self occlusions. They were also manually labelled with joint information of the targeted human. We split the data into 70% training, 15% validation and 15% test.
We collected images from multiple sources and cropped some of them to make all images human centered, we can see this in the following table:

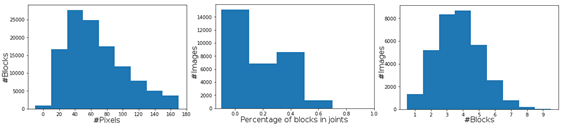
Masks: for each image we generated a different mask to hide part of the image. Algorithms will be evaluated in how well they can restore the parts of the image occluded by this mask. To avoid having fixed bounds we set the following procedure: masks will consist of N blocks, where 0<N<11 for each image, being each block a square of size s ranging from 1/20 of the minimum side of the image to 1/3 of the minimum side. The blocks positions will be mostly random, but they will tend towards covering joints. There will be no overlap between blocks and they will always have a margin of 100px from the image's edge. At most 70% of the image will be masked. We can see the resulting statistics for the masks on the training set.
News
There are no news registered in Image Inpainting (WCCI'18, ECCV'18)